
Why Encode the Journals?
Thoreau has several journal entries from his life in the hands of the scholarly community, but these entries are not encoded, existing only in manuscript and transcript form. This makes it very difficult for scholars to analyze, search through, and work with the texts as they strive to learn more about him and his work. The journal entries provide information about Thoreau that is absent from his books and other published works, and so are of great value to the community. Encoding these entries will make it easier for scholars to find patterns in who he interacted with, where he went, what he observed in nature, and what he did throughout his life.

The Process
Receiving the Journals
Our group got off to a rather late start, in part due to our lack of resources and lack of knowledge about XML and TEI. Within time, we received the files of Thoreau’s journal entries from Beth Witherell over Google Drive, including manuscripts, transcripts, and notes. After receiving the files we began to look through them in search of patterns and themes that we could focus on. Beth Witherell shared sets of journal categories and information so that we would have a starting point for our journey.

The Google Doc
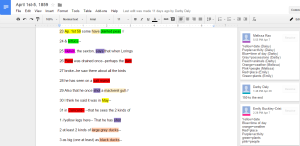
Once we determined the themes that we wanted to focus on, we then created a Google Doc containing the journals that we were going to encode. From here we had to split up the elements that we wanted to identify, and to do so used a color coordination method that consisted of us highlighting the specific words in different colors to make it easier for us to locate them. These elements included dates, activities, times of day, possessions, animals, plants, weather, people, and places. We each picked two elements and went through the document, highlighting their occurrences in several entries.
Going into Depth
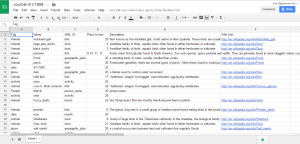
After a discussion with Dr. Schacht we decided to elaborate on the elements that we had identified by providing more information, rather than tagging more elements. This process required us to assign an XML:ID to proper names of people and places, and also include the “ref” attribute within the tags that would link to a website with more information. To do this, we created a spreadsheet listing the tag, XML:ID, name in the text, place in the text, and reference link.
Starting to Encode
We divided up the documents amongst ourselves and started coding with the text editors on our own computers. For this we used both TextWrangler and Notepad ++. We each had approximately sixteen lines to encode and referred back to the spread sheet and GoogleDoc to keep track of our tags.
Challenges
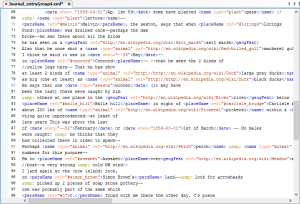
We ran into several roadblocks because TEI does not have have specific tags for elements such as animals, weather, plants, activities, and possessions. With Dr. Schacht’s help we were able to find ways around this problem and use alternative methods to tag plants and animals; however, we were still unable to find tags for weather, possessions, and activities, and had to leave those elements out. This would be more possible for more advanced TEI editors who have more time to focus on this. We also struggled with tagging names, because in the entry we focused on, Thoreau references vague and ambiguous characters, including a person only referred to as “C”. We had to make several decisions on what each element could apply to within the text. For example, did a “salt marsh” count as a place, or should only proper places be included?
Oxygen
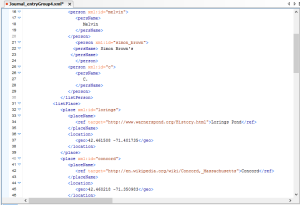
After we tagged the elements individually we combined our individual sections using the more advanced text editor, Oxygen, including a header that was created by Dr. Schacht. We downloaded Oxygen as late as possible into the process in order to utilize the thirty-day free trial. Oxygen was especially helpful because it validated our document as we worked, and gave hints at the source of any issues.

Validating
At one point, we found that several of our XML:IDs were not accepted by Oxygen, and we didn’t know why. Dr. Schacht updated the template he had given us, and explained to us how to include the XML ID’s in the heading rather than within the body of the text, as well as how to have references within the text itself.
Final Meeting
We met with Dr. Schacht with some final inquiries and adjustments to our document. We discussed referring to IDs from the header within the text and tagging geographic features, as well as tagging drawings and uncertain text within the entry. We also adjusted the spacing and formatting of the document. By the end of our meeting, the XML document was complete and validated within oxygen.
Questions
Throughout the process, we had several questions that Beth Witherell may have been able to answer, or possibly provide guidance on. These include:
-
How important is preserving the format of the original journal entry manuscript? For example, we didn’t encode any of the line breaks, page breaks, or paragraphs that were in the manuscript. Additionally, the paragraphs were not included in the transcript we worked from, and the page breaks were not clearly defined.
-
Is the quantity of elements tagged more important than the depth of information provided? For example, we tagged a very general list of elements, but provided further information through the use of reference links. Because of this, there were many tags suggested by Beth Witherell that we did not include.
-
Are there some elements that are more important than others, that you think would provide more insight to Thoreau and his work than others?
-
Are there specific journal entries that would be more beneficial to Thoreau scholars to encode than others?
What We Learned
We learned a lot about encoding throughout this process, especially about the limitations of it. There were several element tags that seemed simple to us and relevant to the text, but the TEI guidelines could not provide. Although these elements could have been customized by us, we did not have the skill nor the time to do so. We also learned that interpreting the manuscripts written by Thoreau is a delicate and difficult process that includes a lot of decision making and judgement on behalf of the interpreter. Finally, we learned that there is a sort of authority given to the encoder, because she decides how elements should be organized, what is important, and what is not.
Group 4 Members: Daisy Anderson, Emily Buckley-Crist, Darby Daly, Melissa Rao
 e are things that I’m sure almost all of us have heard at some point, whether it be from our parents, grandparents, teachers, or maybe even that annoying aunt; but regardless of whoever had said it, there is a good chance that they were most likely a great deal older, having grown up in a generation that was not as heavily reliant on technology as ours is today. Now, it is very easy to just brush off these comments, as most kids our age, and teens especially, clearly know everything. And of course, what would these older folks know? They didn’t have technology like this. They’re obviously just stating that we’re wrong because our lifestyle varies so
e are things that I’m sure almost all of us have heard at some point, whether it be from our parents, grandparents, teachers, or maybe even that annoying aunt; but regardless of whoever had said it, there is a good chance that they were most likely a great deal older, having grown up in a generation that was not as heavily reliant on technology as ours is today. Now, it is very easy to just brush off these comments, as most kids our age, and teens especially, clearly know everything. And of course, what would these older folks know? They didn’t have technology like this. They’re obviously just stating that we’re wrong because our lifestyle varies so much from what theirs once was.
much from what theirs once was. e things may make me sound like a grandma, I would like to point our that there are plenty of studies that prove that this concept is actually true.
e things may make me sound like a grandma, I would like to point our that there are plenty of studies that prove that this concept is actually true. ore so to avoid these situations? Unfortunately there are a lot of difficulties regarding this possible solution. Today’s society is so heavily reliant on technology that, even if the child’s technology use is limited at home, their education will now heavily rely on it as well.
ore so to avoid these situations? Unfortunately there are a lot of difficulties regarding this possible solution. Today’s society is so heavily reliant on technology that, even if the child’s technology use is limited at home, their education will now heavily rely on it as well. 

 ways that your IP address can be obtained, allowing hackers to get into your computer or allowing yourself to get caught for
ways that your IP address can be obtained, allowing hackers to get into your computer or allowing yourself to get caught for