
My project is a text analysis of the works of American women writers in the 19th century. Based off the core texts I read in Dr. Caroline Woidat’s ENGL 439: American Ways: Plotting Women, I hope to prove with digital tools that women writers in this period were intent on tackling pervasive and even controversial social issues. This work will attempt to break down misconceptions that early American women were confined to the sphere of domesticity in their writing by examining their works’ relationships to topics such as slavery, education, economic empowerment, and more.

Establishing connections between literary pieces and historical contexts is a traditional humanities aim, allowing us to understand what these texts may be responding to or influencing. Like many projects, it will focus on identifying trends, patterns, and language to support this goal. The benefit of digital tools, however, is that they allow us to push the boundaries of what a single human scholar can study; using Python, Voyant Tools, and/or other programs with text analysis capabilities, many lifetimes of reading can be processed at once.
One of my main obstacles in tackling this project has been stepping outside of my comfort zone and embracing the broad scope that digital tools can allow my work here to have. I’ve read roughly eight texts for the class this project is stemming from, and I initially intended on just analyzing those – I know them well, which means I can run them through text analysis with the results already envisioned. Below, the spreadsheet I’ve been developing this semester lists these women and their literary works on top:
Discussion in class and my meeting with Kirk Anne, however, have pushed me to include many more writers and texts in this analysis. Kirk can pull every text file from Project Gutenberg (happily, the time period of focus here precedes copyright law) and apply commands to them in order to identify the word choices, patterns, and relationships I’m looking for. That’s tens of thousands of options, which opens up so many opportunities – we could compare trends in women’s writing across time periods, compare them to a canon of typically much more well-known men’s works, etc. There is an honestly overwhelming amount of approaches, but for now, I am focused on finding a wider selection of American female authors within the window of the 19th century, using the writers I initially intended to analyze as major touchpoints.
This process is a challenge in itself, as I find myself running into the most sweeping questions English as a discipline faces – who do we read, and why? Which books and authors should I include, and on what basis? It’s also technically difficult; Project Gutenberg does not make distinctions between male and female authors, so Kirk has been working to parse that out based on name – leaving a massive chunk of authors in uncertain territory. The Excel file he has compiled of all the women writers on Project Gutenberg that he can identify is still monstrous, however!
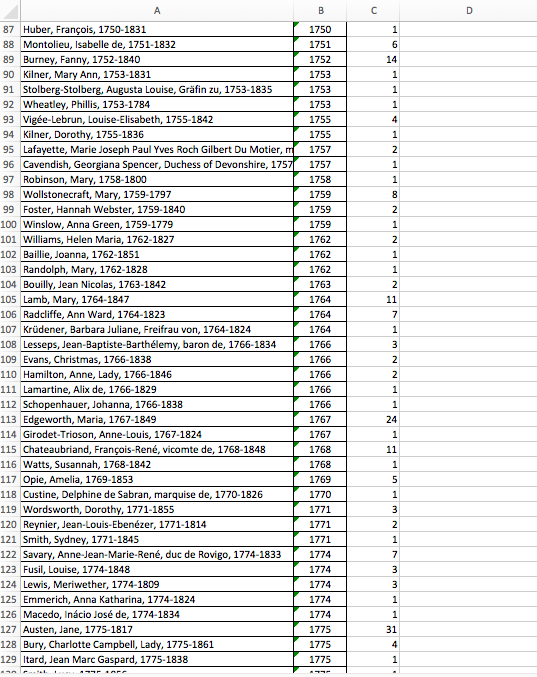
As I broaden my canon, I also have to identify which women are American on my own. I’ve been doing this by cross-referencing the Excel file with some Internet research on women writers within the given period (which, again, brings me back to an ideological conundrum about finding authors who aren’t going to pop up in Wikipedia lists but still had important things to say).

There’s also the question of genre; in my original selection, most texts are fictional novels, but there are lots of women writers in this period who were publishing nonfiction, poetry, or, in Harriet Beecher Stowe’s case, defenses of their own novels. There’s a lot I’d like to include that will force me to really consider how comparable different types of texts are and where data might be skewed.
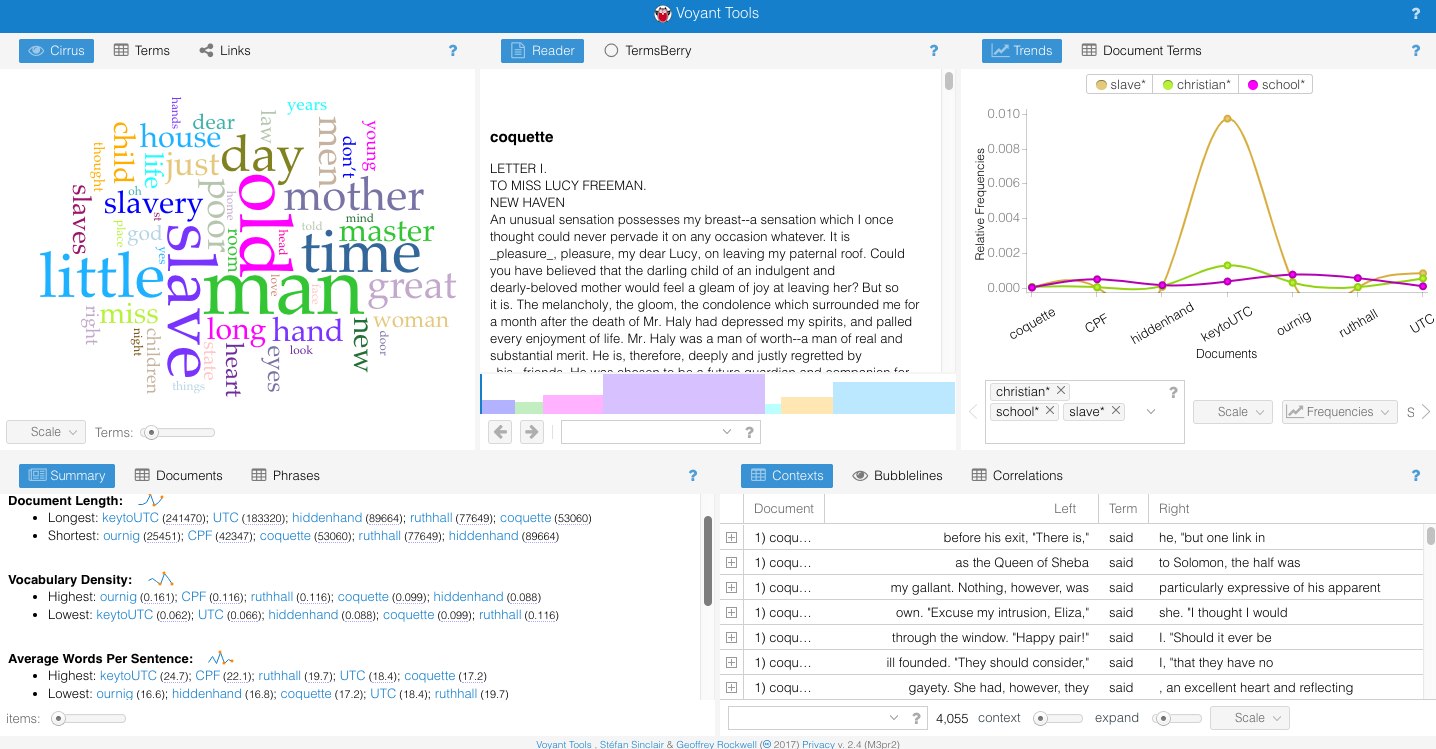
Another, less mind-boggling obstacle is just my level of technical proficiency. Voyant Tools, intended for this type of digital scholarship, has been a great free resource for me as I begin to explore the connections between texts and social concerns on my own. With these, I can create frequency-based word clouds using the Cirrus tool, visualize the relative frequencies of word usages across all my texts with a graph, and get some data about which texts are longest and use the most unique words. Voyant Tools is user-friendly; you simply upload the text files you intend to use and it runs them for you on their website. Then, you can change which tools you’re using, make your own restrictions as to which words you want to search for within texts, and then export the results as images or embeddable HTML.
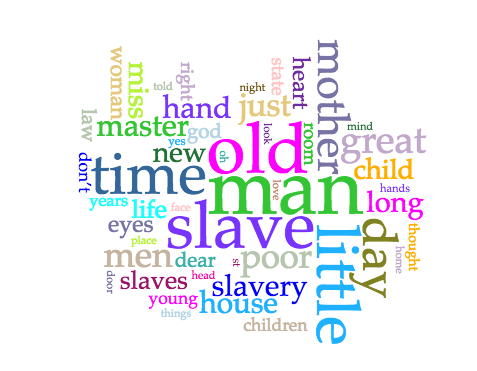
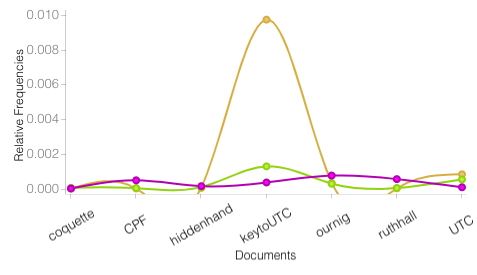
Voyant Tools does have significant limits when it comes to more advanced or particular text analysis attempts, which means Kirk Anne has been doing a ton of work on this project, pulling files and running his own commands. I do not have the programming knowledge to carry much of this out, which means I’m really going to be relying on his expertise and working to decide what I want to look for and how that can be pulled off. I’ve been really impressed with the range of possibilities this has opened up; for me, analyzing texts has always meant closely reading them, whereas he can find patterns in over 10,000 works at once.
Once I finalize my list of texts, I can start delving into finding the patterns I’m hoping to identify. In the next few weeks, I can hopefully compile some interesting results and display them – which leads to more choices and digital tools, for I am debating creating a WordPress to host this project and also developing a TimelineJS timeline of the women writers being showcased.