This project was centered on finding ways to apply previously completed scholarly work on Walden to the digital frame of our class. Donald Ross played a major role in analyzing the different versions of Walden, as well as tracing the inspiration for many of Thoreau’s messages. Ross was able to draw connections between Walden’s narrative to major ideas such as Biblical allusions, references to Eastern Philosophy, and so on. Our mission for the semester was to take Ross’ information and translate it into a form that we could use for the Fluid Text edition of Walden.
 Our first obstacle was simply figuring out how to start; Ross’ materials stretched on for 72 pages of dense information, most of which we spent a good deal of time trying to decipher. We settled on using R to analyze Walden, using digital methods to parse out Walden the same way that Ross did by hand. By doing this we were able to test out the possibilities and limits of digitally analyzing a work of literature by comparing it to the analysis of the same work by a human scholar.
Our first obstacle was simply figuring out how to start; Ross’ materials stretched on for 72 pages of dense information, most of which we spent a good deal of time trying to decipher. We settled on using R to analyze Walden, using digital methods to parse out Walden the same way that Ross did by hand. By doing this we were able to test out the possibilities and limits of digitally analyzing a work of literature by comparing it to the analysis of the same work by a human scholar.
What we found was that R has a huge amount of potential in this field, though it will take some work to fully reach that potential. The way the analysis worked was by searching for “n-grams,” or a set of n number of words (in our case 5), looking for matches between Walden and other specified books. The n-grams were compiled into a spreadsheet which showed us the word matches along with the entire sentence of Walden and the entire sentence of the other work. The program found over 2,000 n-grams, most of which were coincidences driven by similar word-usage. We focused on the Biblical references Thoreau is notorious for, and so scrolled through the enormous spreadsheet searching for n-grams that held deeper meaning than simple coincidence.
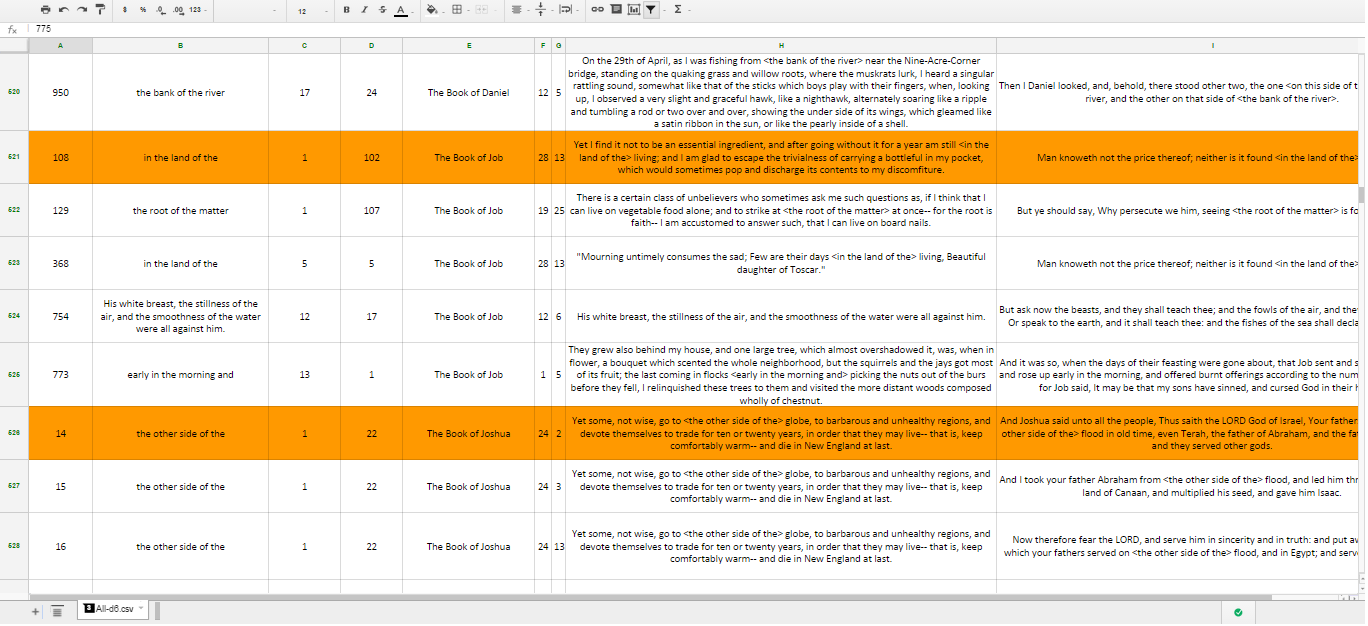
The program written for the analysis performed by R was still in its early stages and yet was able to perform the analysis in a number of hours; surely record time in the field of literary analysis.
There is clearly a lot of future work that can be put into this project. Sifting through the information example by example was a lengthy process, even with three people working simultaneously. As a result, our group only managed to make a modest dent in the material. We only focused on the Biblical allusions Ross found in Walden, passing up his lists of allusions to Eastern philosophers, verbal wit, and other categories. We also only managed to sift through a fraction of what the R program additionally found. Although most of these were coincidental, one of them seemed to be an honest Biblical allusion that Ross overlooked. There could be many more that Ross didn’t find, but that we were simply unable to get to in the allotted time.
Overall we have looked at the program as a success. After sifting through the bibical references that Harding had already found and comparing them to what the computer found, the computer was able to pick up on one more reference that Ross had missed. While this may seem like a small victory compared to the thousands of invalid references that the computer had found, it must be considered that the references were found in a matter of hours and the program is still in its early stages. While it may have taken Ross months to be able to find these references, the computer was able to do it in just a few hours. We believe this project has some real potential to affect the Digital Humanities, and there is a lot more work to be done.